|
竞技宝官网app·Sora一旦推出峰值算力需要75万张H100GPUSora何时推出?大约在年底。它非常受欢迎,一旦投入使用,不仅会对影视行业造成冲击,而且会在视频网站、社交媒体、电商平台,以及教育等领域得到广泛应用。它的物理世界模拟器的作用,以及“世界模型”的潜力也非常巨大。 作者假设Sora推出后,将在Tiktok和Youtube上得到广泛的应用,推算出需要的算力相当于72万张英伟达H100 GPU。对比一下,目前Meta拥有的总算力,相当于65万张H100。
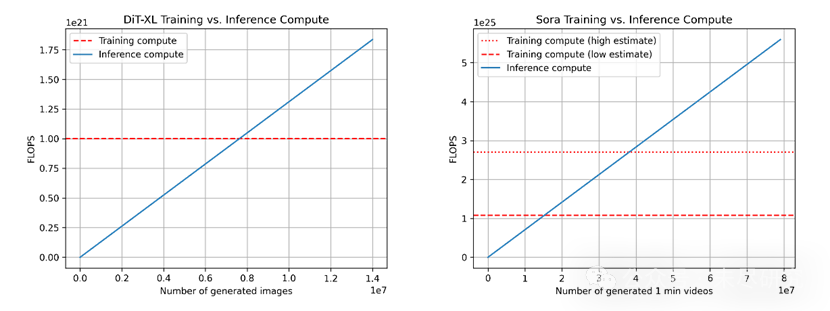
关于Sora的细节信息非常少,但我们可以再次查看显然是Sora基础的DiT论文,并从中推断出相关的计算数字。最大的DiT模型DiT-XL有6.75亿个参数,总计算预算约为10^21次浮点运算。为了更容易理解这个数字,这相当于大约0.4个Nvidia H100 GPU运行一个月(或一个H100运行12天)。 但是目前DiT仅对图像建模,而Sora是一个视频模型。Sora可以生成长达1分钟的视频。如果我们假设视频以24帧/秒编码,一个视频最多包含1440帧。Sora的像素到潜在映射似乎在空间和时间上都有压缩。如果我们假设与DiT论文中相同的压缩率(8倍),我们最终在潜在空间中得到180帧。因此,在直观地将DiT外推到视频时,我们得到了180倍的计算量倍增因子。 我们进一步认为,Sora的参数量明显大于6.75亿个。我们估计200亿参数的模型是可行的,这使我们在计算量上比DiT再多出30倍。 最后,我们认为Sora使用的训练数据集比DiT大得多。DiT在批量大小为256时经过300万步训练,即总计使用了7.68亿张图像(但要注意同一数据被重复使用了多次,因为ImageNet仅包含1400万张图像)。Sora似乎是在图像和视频的混合数据集上进行训练的,但除此之外我们几乎一无所知。 因此,我们简单假设Sora的数据集中有50%是静止图像,50%是视频,并且数据集比DiT使用的大10到100倍。然而,DiT在相同的数据点上反复训练,如果有更大的数据集可用,这种做法可能是次优的。因此,我们认为4到10倍的计算量倍增因子是一个更合理的假设。 另一个值得考虑的重要因素,是训练计算与推理计算之间的对比。训练计算量非常大,但这是一次性的成本。相比之下,推理计算量虽然小得多,但每一次生成都意味着一次推理计算。因此,推理计算量会随着用户数量的增加而扩大,并变得越来越重要,特别是当一个模型被广泛使用时。 因此,观察“收支平衡点”是很有用的,即消耗在推理计算上的计算量,超过了训练期间消耗的计算量的时间点。
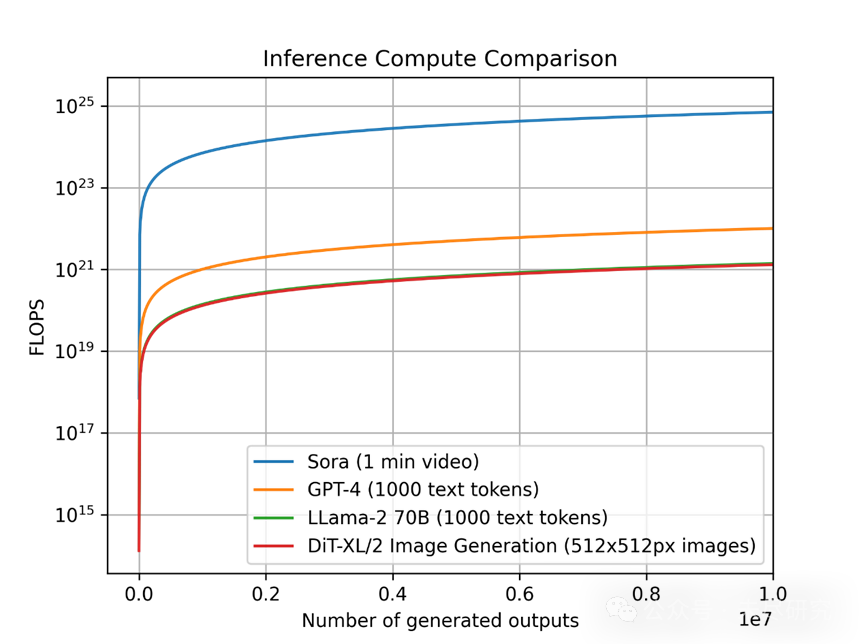
(左图对比DiT的训练与推理计算,右图对比Sora的训练与推理计算。对于Sora部分,我们的数据基于上文估计,因此不是完全可靠。我们还展示了两种训练计算的估计:一种低估计(假设数据集大小的倍增因子为4倍)和一种高估计(假设为10倍)。) 在上述数字中,我们再次利用DiT来推算Sora。对于DiT,最大的模型(DiT-XL)每步使用524×10^9次浮点运算,DiT使用250步扩散生成单张图像,因此总计为131×10^12次浮点运算。我们可以看到,收支平衡点在生成760万张图像后达到,此后推理计算将占主导。作为参考,用户每天大约上传9500万张图像到Instagram。 对于Sora,我们将浮点运算次数外推为524×10^9次× 30 × 180 ≈ 2.8×10^15次。如果我们仍然假设每段视频需250步扩散,那就是每段视频总计708×10^15次浮点运算。作为参考,这大约相当于每小时每个Nvidia H100生成5分钟视频。 收支平衡点在生成1530万(低估计)到3810万(高估计)分钟视频后达到,之后推理计算将超过训练计算。作为参考,每天约有4300万分钟视频上传到YouTube。 需要注意的是:对于推理来说,浮点运算次数并不是唯一重要的因素。内存带宽也是另一个重要因素。此外,现有研究正致力于减少所需的扩散步数,这可能导致推理计算量大幅降低,因此推理速度会更快。训练和推理阶段的浮点运算利用率也可能有所不同,在这种情况下,它们就变得很重要了。 我们还观察了不同模态下不同模型的每单位输出推理计算量。这里的想法是,看看不同类型模型的推理计算量级别有多大差异,这对于规划和预测计算需求有直接影响。重要的是,我们要理解,由于不同模型工作于不同的模态,每个模型的输出单位也不尽相同:对于Sora,单个输出是一段1分钟长的视频;对于DiT,是一张512x512像素的图像;而对于Llama 2和GPT-4,我们将单个输出定义为一份长度为1000个token的文本文档。
(比较不同模型每单位输出的推理计算量,对于Sora是1分钟视频,对于GPT-4和LLama 2是1000个token的文本,对于DiT是单张512x512像素的图像。我们可以看到,我们对Sora推理的估计比其他模型昂贵,要高出数个数量级。) 我们比较了Sora、DiT-XL、LLama 2 70B和GPT-4,并以对数刻度绘制了它们的浮点运算次数。对于Sora和DiT,我们使用上文的推理估计值。对于Llama 2和GPT-4,我们使用经验公式浮点运算次数=2×参数数量×生成的token数来估计。对于GPT-4,我们假设它是一个混合专家(MoE)模型,每个专家有220B参数,每次前向传递激活2个专家。需要注意的是,GPT-4的这些数字未得到OpenAI的确认,因此也需要谨慎对待。 我们可以看到,基于扩散模型如DiT和Sora的推理算力需求要大得多:DiT-XL(6.75亿参数)的推理计算量,大约与LLama 2(700亿参数)相当。我们还可以看到,Sora的推理算力需求比GPT-4高出数个数量级。 需要注意的是,上述许多数字都是估计值,并且依赖于简化的假设。例如,它们并未考虑GPU的实际浮点运算利用率、内存容量和带宽限制以及诸如推测解码等高级技术。 在这一部分,我们根据Sora的计算需求,推测如果AI生成视频在流行视频平台如TikTok和YouTube上占有重要市场份额,将需要多少英伟达H100 GPU来运行类似Sora的模型。 我们假设每小时每个H100生成5分钟视频(详见上文),相当于每天每个H100生成120分钟视频。 TikTok:每天1700万分钟视频(3400万个视频x平均30秒长度),假设AI渗透率50%。 我们假设100%的浮点运算利用率,并未考虑内存和通信瓶颈。实际上50%的利用率更为现实,需要乘以2倍。 需求不会均匀分布在时间上,而是具有突发性。峰值需求尤其成问题,因为需要相应更多GPU来满足所有流量。我们认为,应考虑峰值需求再增加2倍,作为所需最大GPU数量。 创作者可能会生成多个候选视频,从中挑选最佳。我们保守地假设,平均每个上传视频要生成2个候选视频,再增加2倍。 这说明了我们的观点:随着生成式AI模型变得越来越受欢迎和受到依赖,推理计算将占主导地位。对于基于扩散的模型如Sora,这种趋势会更加明显。 另外需要注意,如果扩大模型规模,推理计算需求也会大幅增加。另一方面,更优化的推理技术和整个技术栈上的其他优化措施,可能会在一定程度上抵消这种影响。 竞技宝官网app |